# 技术培训
# 1 前端
# 1.1 Vue技术
# 1.1.1 Vue组件通信(父传子、子传父、兄弟传值)
# (1)父组件传到子组件
父组件是通过props属性给子组件通信的
数据是单向流动 父—>子 (子组件中修改props数据,是无效的,会有一个红色警告)
父组件parent.vue代码如下:
子组件son代码如下:
子组件接收到内容:
# 子组件通过props来接受数据
# 第一种方法
props: ['childCom']
# 第二种方法
props: {
childCom: String //这里指定了字符串类型,如果类型不一致会警告的哦
}
# 第三种方法
props: {
childCom: {
type: String,
default: 'sichaoyun'
}
}
# (2)子组件向父组件传值
通过绑定事件然后及$emit传值
vue2.0只允许单向数据传递,我们通过出发事件来改变组件的数据
1.父组件parent代码如下:
<template>
<div class="parent">
<h2></h2>
<p>父组件接手到的内容:</p>
<son psMsg="我是你爸爸" @transfer="getUser"></son>
<!-- 监听子组件触发的transfer事件,然后调用getUser方法 -->
</div>
</template>
<script>
import son from './Son'
export default {
name: 'HelloWorld',
data () {
return {
msg: '父组件',
username:'',
}
},
components:{son},
methods:{
getUser(msg){
this.username= msg
}
}
}
</script>
父组件通过绑定自定义事件,接受子组件传递过来的参数
2.子组件son代码如下:
<template>
<div class="son">
<p></p>
<p>子组件接收到内容:</p>
<!--<input type="text" v-model="user" @change="setUser">-->
<button @click="setUser">传值</button>
</div>
</template>
<script>
export default {
name: "son",
data(){
return {
sonMsg:'子组件',
user:'子传父的内容'
}
},
props:['psMsg'],
methods:{
setUser:function(){
this.$emit('transfer',this.user)//触发transfer方法,this.user 为向父组件传递的数据
}
}
}
</script>
子组件通过$emit触发父组件上的自定义事件,发送参数
# (3)非父子传参(兄弟传参、隔代传参等)
假设你有两个Vue组件需要通信: A 和 B ,A组件按钮上面绑定了点击事件,发送一则消息,B组件接收。
# 1. 初始化,全局创建$bus
直接在项目中的 main.js 初始化 $bus :
// main.js
window.$bus=new Vue();
注意,这种方式初始化一个全局的bus 。
# 2. 发送事件
$bus.$emit("aMsg", '来自A页面的消息');
<!-- A.vue -->
<template>
<button @click="sendMsg()">-</button>
</template>
<script>
//import $bus from "../bus.js";
export default {
methods: {
sendMsg() {
$bus.$emit("aMsg", '来自A页面的消息');
}
}
};
</script>
接下来,我们需要在 B页面 中接收这则消息。
# 3. 接收事件
$bus.$on("事件名",callback)
<!-- IncrementCount.vue -->
<template>
<p></p>
</template>
<script>
//import $bus from "../bus.js";
export default {
data(){
return {
msg: ''
}
},
mounted() {
$bus.$on("aMsg", (msg) => {
// A发送来的消息
this.msg = msg;
});
}
};
</script>
# 扩展
# 事件总线推荐下面写法
集中式的事件中间件就是 Bus。我习惯将bus定义到全局:
app.js
var eventBus = {
install(Vue,options) {
Vue.prototype.$bus = vue
}
};
Vue.use(eventBus);
然后在组件中,可以使用$emit, $on, $off 分别来分发、监听、取消监听事件:
# 分发事件的组件
methods: {
todo: function () {
this.$bus.$emit('todoSth', params); //params是传递的参数
}
}
# 监听的组件
created() {
this.$bus.$on('todoSth', (params) => { //获取传递的参数并进行操作
//todo something
})
},
// 最好在组件销毁前
// 清除事件监听
beforeDestroy () {
this.$bus.$off('todoSth');
}
如果需要监听多个组件,只需要更改 bus 的 eventName:
created() {
this.$bus.$on('firstTodo', this.firstTodo);
this.$bus.$on('secondTodo', this.secondTodo);
},
// 清除事件监听
beforeDestroy () {
this.$bus.$off('firstTodo', this.firstTodo);
this.$bus.$off('secondTodo', this.secondTodo);
}
# 理论
1.父传子: 在父组件的子组件标签上绑定一个属性,挂载要传输的变量。在子组件中通过props来接受数据,props可以是数组也可以是对象,接受的数据可以直接使用 Bus.$off(“事件名”)
2.子传父:
vue2.0只允许单向数据传递,我们通过出发事件来改变组件的数据
在父组件的子组件标签上通过绑定自定义事件,接受子组件传递过来的事件。子组件通过$emit触发父组件上的自定义事件,发送参数(第一个是要改变的属性值,第二个是要发送的参数)
3.兄弟组件传值:
通过main.js初始化一个全局的$bus,在发送事件的一方通过$bus.$emit(“事件名”,传递的参数信息)发送,在接收事件的一方通过$bus.$on("事件名",参数)接收传递的事件
Bus.$on(“事件名”)
# 2 后端
# 2.1 代码计时器(用来优化代码执行速度)
TimeInterval timer = DateUtil.timer();
//---------------------------------
//-------这是执行过程
//---------------------------------
Console.log( timer.interval());//花费毫秒数
Console.log( timer.intervalRestart());//返回花费时间,并重置开始时间
Console.log( timer.intervalMinute());//花费分钟数
# 2.2 拦截器和过滤器
# 2.2.1 拦截器和过滤器的区别
1、过滤器和拦截器触发时机不一样,过滤器是在请求进入容器后,但请求进入servlet之前进行预处理的。请求结束返回也是,是在servlet处理完后,返回给前端之前。
2、拦截器可以获取IOC容器中的各个bean,而过滤器就不行,因为拦截器是spring提供并管理的,spring的功能可以被拦截器使用,在拦截器里注入一个service,可以调用业务逻辑。而过滤器是JavaEE标准,只需依赖servlet api ,不需要依赖spring。
3、过滤器的实现基于回调函数。而拦截器(代理模式)的实现基于反射
4、Filter是依赖于Servlet容器,属于Servlet规范的一部分,而拦截器则是独立存在的,可以在任何情况下使用。
5、Filter的执行由Servlet容器回调完成,而拦截器通常通过动态代理(反射)的方式来执行。
6、Filter的生命周期由Servlet容器管理,而拦截器则可以通过IoC容器来管理,因此可以通过注入等方式来获取其他Bean的实例,因此使用会更方便。
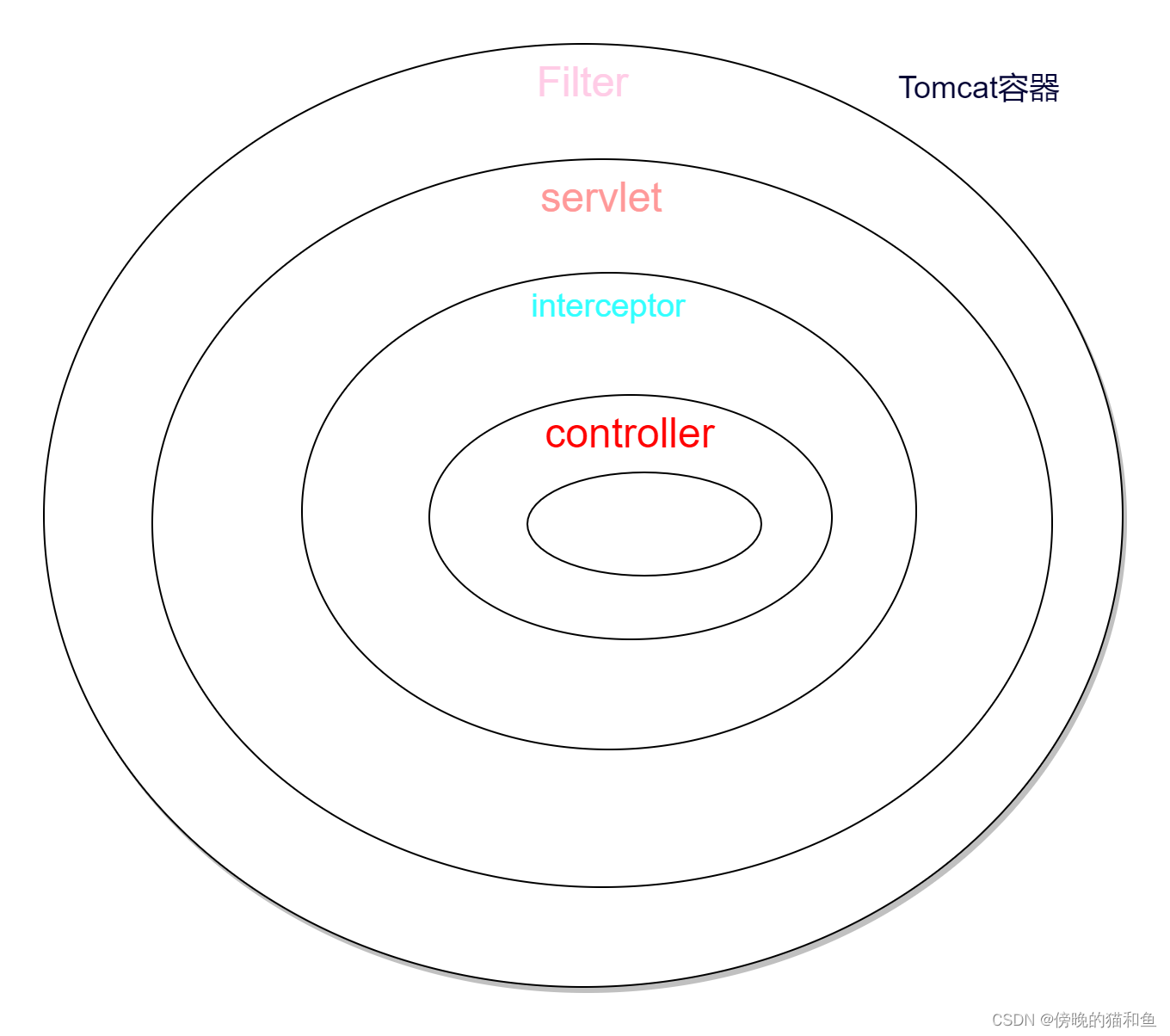 最简单明了的区别:
1.过滤器可以修改request,而拦截器不能
2.过滤器需要在servlet容器中实现,拦截器可以适用于javaEE,javaSE等各种环境
3.拦截器可以调用IOC容器中的各种依赖,而过滤器不能
4.过滤器只能在请求的前后使用,而拦截器可以详细到每个方法
调用方法流程如下:
最简单明了的区别:
1.过滤器可以修改request,而拦截器不能
2.过滤器需要在servlet容器中实现,拦截器可以适用于javaEE,javaSE等各种环境
3.拦截器可以调用IOC容器中的各种依赖,而过滤器不能
4.过滤器只能在请求的前后使用,而拦截器可以详细到每个方法
调用方法流程如下:
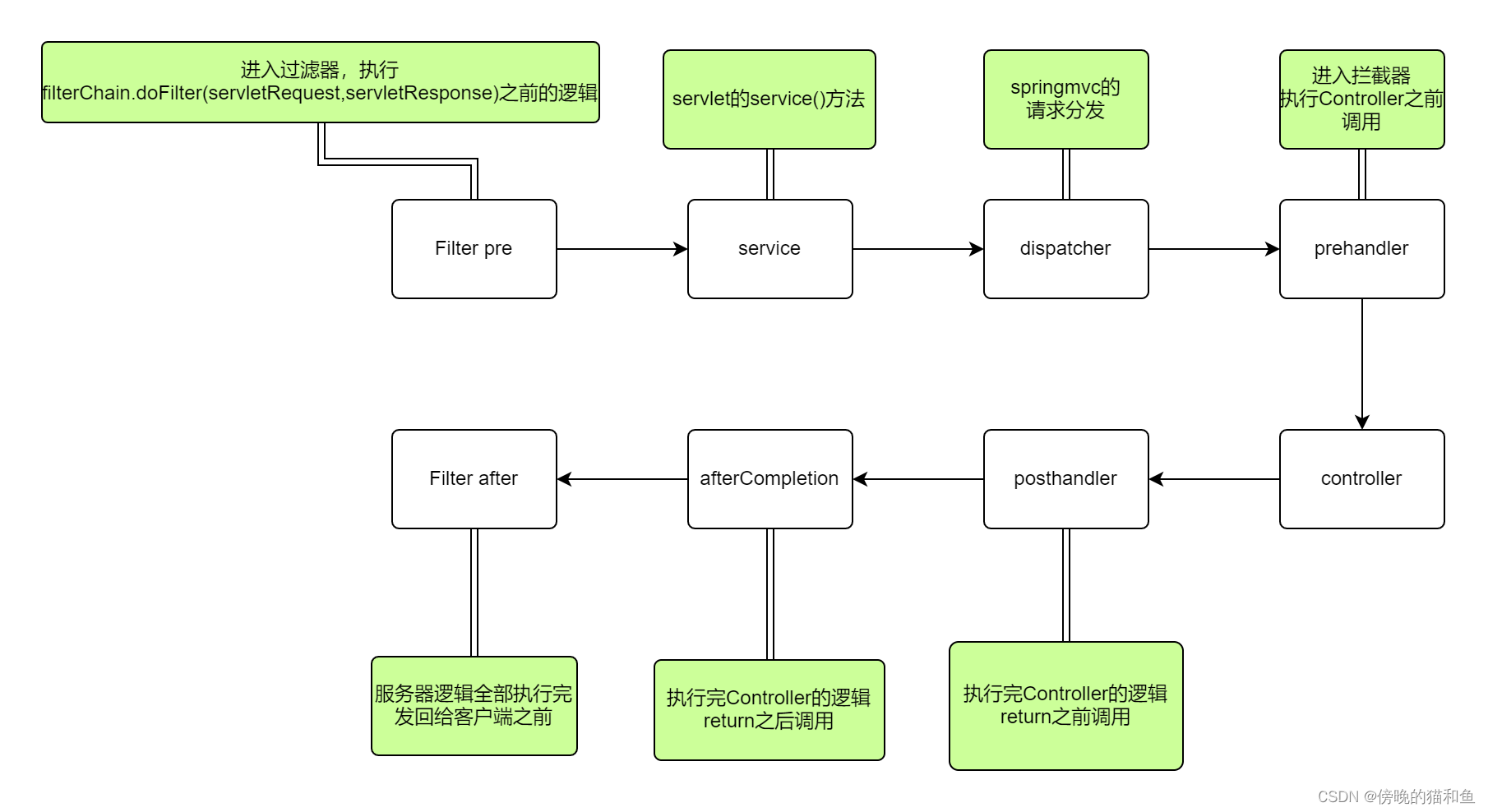
# 2.2.2 过滤器
# 1、 实现方式
1.使用spring boot提供的FilterRegistrationBean注册Filter 定义Filter:
public class MyFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
Filter.super.init(filterConfig);
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
log.info("MyFilter");
}
@Override
public void destroy() {
Filter.super.destroy();
}
}
12345678910111213141516
注册Filter:
@Slf4j
@Order(1)
public class MyFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
Filter.super.init(filterConfig);
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
log.info("-----------------------MyFilter");
filterChain.doFilter(servletRequest,servletResponse);
}
@Override
public void destroy() {
Filter.super.destroy();
}
123456789101112131415161718
2.使用原生servlet注解定义Filter
@WebFilter(filterName = "LoginFilter" ,urlPatterns = "/*")
@Slf4j
@Order(2)
public class LoginFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
log.info("进入过滤器init");
Filter.super.init(filterConfig);
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
log.info("进入过滤器"+servletRequest.getRemoteAddr()+"|"+servletRequest.getRemoteHost()+"|"+servletRequest.getLocalPort()+"|"+servletRequest.getServerPort()
);
filterChain.doFilter(servletRequest,servletResponse);
}
@Override
public void destroy() {
log.info("进入过滤器destroy");
Filter.super.destroy();
}
12345678910111213141516171819202122
这里直接用@WebFilter就可以进行配置,同样,可以设置url匹配模式,过滤器名称等。这里需要注意一点的是@WebFilter这个注解是Servlet3.0的规范,并不是Spring boot提供的。除了这个注解以外,我们还需在启动类中加另外一个注解:@ServletComponetScan,指定扫描的包。
# 2、应用场景
1)过滤敏感词汇(防止sql注入) 2)设置字符编码 3)URL级别的权限访问控制 4)压缩响应信息
# 2.2.2 拦截器
# 1、实现方式
1.自定义拦截器
@Slf4j
public class AuthInterceptor implements HandlerInterceptor {
@Override public boolean preHandle(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, Object o) throws Exception {
log.info("preHandle");
String clientIP = ServletUtil.getClientIP(httpServletRequest);
log.info("访问IP:"+clientIP);
log.info("请求路径:{}", httpServletRequest.getRequestURI());
return true;
}
@Override public void postHandle(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, Object o, ModelAndView modelAndView) throws Exception {
log.info("postHandle");
}
@Override public void afterCompletion(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, Object o, Exception e) throws Exception {
log.info("afterCompletion");
}
123456789101112131415161718
2.注册拦截器
@Configuration
public class WebMvcConfig extends WebMvcConfigurationSupport {
private final AuthInterceptor authInterceptor;
public WebMvcConfig(AuthInterceptor authInterceptor) {
this.authInterceptor = authInterceptor;
}
@Override
protected void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(authInterceptor)
.addPathPatterns("/**");
}
}
123456789101112131415
# 2.2.3 应用场景
1.登录验证,判断用户是否登录。 2.权限验证,判断用户是否有权限访问资源,如校验token 3.日志记录,记录请求操作日志(用户ip,访问时间等),以便统计请求访问量。 4.处理cookie、本地化、国际化、主题等。 5.性能监控,监控请求处理时长等。 6.通用行为:读取cookie得到用户信息并将用户对象放入请求,从而方便后续流程使用,还有如提取Locale、Theme信息等,只要是多个处理器都需要的即可使用拦截器实现)
# 2.3 Redis 经验之谈
redis是性能比较好的nosql,这里总结下个人使用的经验总结:
- 【key命名】
1、全局规划,key值前缀作为命名空间 : key - value第一级的key值前缀要全局规划好,避免冲突导致互相覆盖。 2、key不要包含空格符,命名不要过长 : 含有空格容易导致输入错误,命名过长浪费内存空间。 3、key前缀不要出现魔鬼数字,防止硬编码 : key值前缀应该要清晰明了,容易理解。
- 【内存】
1、避免内存泄露 : redis是内存数据库,随着数据的越来越多,占用会越来越大,要注意垃圾回收,定期清理垃圾数据。 2、合理规划内存占用,养成节约内存的习惯: 1)收到系统最大内存限制,一般应用实例缓存控制在最大内存的2/3以内。 2)大数据内存占用应该接近实际存储容量,但还要实测分析内存占用是否合理 3)预留一定的内存空间,一般redis只适用机器内存1/2到2/3,内存其实分为两部分: - 缓存数据占用的内存,对应于redis.conf配置的maxmemory。 - 处理高并发请求分配的临时内存,并发请求越多,临时内存越多。 3、key的数量越少越好 : 减少key数量可以降低内存开销 4、权衡value的取值为,尽量使用纯数字可以节省内存:比如把“true”改为1,“false”改为 0。
- 【事务】
1、优先使用批量接口获取批量数据: redis的交互越多越耗时,另外也不能保证其原子性,使用redis批量接口命令,其次才使用事务。 2、集合操作为主的业务考虑使用set数据结构:set有丰富的去交集、差集等命令,简单高效,保证了事务的原子性。 3、redis只支持简单事务,redis事务是一个隔离的操作,事务中的所有命令都会序列化,按顺序执行,事务的执行过程中,不会被其他客户端发过来的命令请求所打断。 4、redis对事务的支持没有其他关系型数据库那么强大,redis在事务失败时不会进行回滚,而是继续执行余下命令,它不保证原子性(所有指令同时成功或同时失败)。只有决定开始执行全部指令的能力,没有执行到一半回滚的管理。如果事务执行到一半redis被kill掉,已经执行的指令同样不会被回滚。
- 【性能】
1、尽量减少和redis的交互次数:交互的越多越耗时,另外原子性也得不到保证,尽量使用批量命令。 2、调优参数 : 通过调整set_max_inset_entries参数,从def的512调整到1024。但是占用内存会增大。 3、redis最佳使用方式是cache非持久化:其他模式会占用更多的资源,需要根据具体项目做决定。
- 【可靠性】
1、需要定时监控redis的健康情况:使用各种redis健康监控工具,实在不行可以定时返回redis 的 info信息。 2、客户端连接尽量使用连接池(长链接和自动重连)
- 【安全性】
1、无用户管理和权限管理: 全局只有一个超户,对应一个密码。 2、不安全的客户端访问方式。
redis不适合作为海量数据存储方案,redis适合在数据规模较小,性能要求较高的条件下使用。
# 3 前后端工作安排
# 一、前后端分离的基本概念
前端后端交互,基本上是基于http+json的形式。后端专注于提供数据,更重要职责是维护系统架构的稳定,保证数据的安全。前端人员专注于交互,快速响应UI的变化。
双方交互基于http+json接口,后端人员基本只对接口负责,无需负责js和html的代码。前端人员只对界面展示交互负责,对于后端http接口如何提供正确的数据无需负责。
前后端分离的主要概念就是:后台只需提供API接口,前端调用AJAX实现数据呈现。
# 二:前后端分离的意义
1:彻底解放前端,前端不再需要向后台提供模板或是后台在前端html中嵌入后台代码
2:提高工作效率,分工更加明确,前后端分离的工作流程可以使前端只关注前端的事,后台只关心后台的活,两者开发可以同时进行,在后台还没有时间提供接口的时候,前端可以先将数据写死或者调用本地的json文件即可,页面的增加和路由的修改也不必再去麻烦后台,开发更加灵活。
3:局部性能提升,通过前端路由的配置,我们可以实现页面的按需加载,无需一开始加载首页便加载网站的所有的资源,服务器也不再需要解析前端页面,在页面交互及用户体验上有所提升。
4:降低维护成本,通过目前主流的前端MVC框架,我们可以非常快速的定位及发现问题的所在,客户端的问题不再需要后台人员参与及调试,代码重构及可维护性增强。
5、有利于产品的组件化,由于前后端分离,有利于迅速二次开发推出新产品。
6、减少后端新人上手项目的难度,提高产品的可维护性和可拓展性。
7、基于原有后端接口,有利于后期在安卓,ios,微信等其他不同平台进行产品二次开发。
# 三:实现分离的基本合作思路
1、评审阶段:产品经理与前后端进行需求评审,各自理解清楚自己的业务量以及联调的工作量,评估开发时间。
2、开发准备阶段:前后端一起商量需求中需要联调的部分,进行接口的口头协议交流。
3、接口定义阶段:前后端一方中,前后端中的一方根据之前的口头协议拟定出一份详细的接口,并编写服务接口定义,完成后由另一方确认。有疑问的地方重新商量直至双方都没有问题。
4、开发阶段:双方根据协商出来的接口为基础进行开发,如在开发过程中发现需要新增或删除一些字段,重复步骤3。
(注意:前端在开发过程中记得跟进接口,mock数据进行本地测试,后端修改接口需要跟前端协商清楚再改。 )
5、联调阶段:双方独自的工作完成,开始前后端联调,如在联调过程发现有疑问,重复步骤3,直至联调完成。
6、提测阶段:将完成的需求提给测试人员,让其对该需求进行测试,如发现问题,及时通知开发并让其修改,直至需求没有bug。
7、发布阶段:前后端双方在保证步骤1-5都没有问题了,进行各自的代码发布,完成后由测试人员在线上进行相应的测试,如果有bug,重复步骤6和7,直至成功上线。
# 四:相关问题及解决建议
1、前后端分离会带来前后端沟通成本的问题,相比不分离,能减少开发的总时间吗?
能减少开发的总时间,理由如下:
(1)、基于对接口负责的原则,前后端分离后,只需做好各种熟悉领域的事情。
后端专注于提供数据,更重要职责是维护系统架构的稳定,保证数据的安全。
前端人员专注于交互,快速响应UI的变化。
(2)、前后端分离确实会带来沟通成本的问题,这方面需要前后端遵守合作流程,适应新的合作模式,可以提高沟通效率。总体而言,利大于弊。
2、接口定义阶段,接口谁定?
回答:建议后端开发人员定,需要前端人员评审。
3、联调阶段,前端是基于后端的开发人员的机器联调,还是基于后端一个开发公共环境联调?
回答:前端应该基于后端的一个公共开发环境联调,理由如下:
(1)、开发过程中,后端开发人员机器环境不稳定,后端人员在调速中会时不时进行断点调试,重启机器的服务器。
(2)、公共开发环境由开发人员负责更新程序,并需要在更新程序前把代码提交代码仓库,这样有利于前端有一个实时更新,稳定的调试环境。
# 前后端分离的核心:后台提供数据,前端负责显示
← 设计模式笔记